Xiao Qin's Research
Final Report
BUD: A Buffer-Disk Architecture for Energy Conservation in Parallel Disk Systems
Findings
An Energy-Efficient Framework for Large-Scale Parallel Storage Systems
A Simulation Framework for Energy-efficient Data Grids
An Energy-Efficient Scheduling Algorithm Using Dynamic Voltage Scaling
for Parallel Applications on Clusters
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Sacrificing Reliability for Energy Saving: Is It Worthwhile for Disk Arrays
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Energy-Efficient Prefetching for Parallel I/O Systems with Buffer Disks
Improving Reliability and Energy Efficiency of Disk Systems via Utilization Control
Energy Conservation for Real-Time Disk Systems with I/O Burstiness
An Adaptive Energy-Conserving Strategy for Parallel Disk Systems
DARAW: A New Write Buffer to Improve Parallel I/O Energy-Efficiency
MICRO: A Multi-level Caching-based Reconstruction Optimization for Mobile Storage Systems
PEARL: Performance, Energy, and Reliability Balanced Dynamic Data Redistribution for Next Generation Disk Arrays
HyBUD: An Energy-Efficient Architecture for Hybrid Parallel Disk Systems
Energy-Aware Prefetching for Parallel Disk Systems
DORA: A Dynamic File Assignment Strategy with Replication
Collaboration-Oriented Data Recovery for Mobile Disk Arrays
A File Assignment Strategy Independent of Workload Characteristic Assumptions
References
[Nijim et al., 2008a] In the past decade parallel disk systems have been highly scalable and able to alleviate the problem of disk I/O bottleneck, thereby being widely used to support a wide range of data- intensive applications. Optimizing energy consumption in parallel disk systems has strong impacts on the cost of backup power-generation and cooling equipment, because a significant fraction of the operation cost of data centres is due to energy consumption and cooling. Although a variety of parallel disk systems were developed to achieve high performance and energy efficiency, most existing parallel disk systems lack an adaptive way to conserve energy in dynamically changing workload conditions. To solve this problem, we develop an adaptive energy-conserving algorithm, or DCAPS, for parallel disk systems using the dynamic voltage scaling technique that dynamically choose the most appropriate voltage supplies for parallel disks while guaranteeing specified performance (i.e., desired response times) for disk requests.
The DCAPS algorithm aims at judiciously lower the parallel disk system voltage using dynamic voltage scaling technique or DVS, thereby reducing the energy consumption experienced by disk requests running on parallel disk systems. The processing algorithm separately repeats the process of controlling the energy by specifying the most appropriate voltage for each disk request. Thus, the algorithm is geared to adaptively choose the most appropriate voltage for stripe units of a disk request while warranting the desired response time of the request.
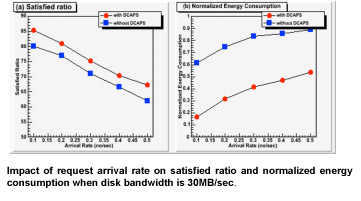
The above two Figures plot the satisfied ratios, normalized energy consumption, and energy conservation ratio of the parallel disk systems with and without DCAPS. Figs 3(a) reveals that the DCAPS scheme yields satisfied ratios that are very close to those of the parallel disk system without employing DCAPS. This is essentially because DCAPS endeavors to save energy consumption at the marginal cost of satisfied ratio. More importantly, Figs. 3(b) and 4 show that DCAPS significantly reduces the energy dissipation in the parallel disk system by up to 71% with an average of 52.6%. The improvement in energy efficiency can be attributed to the fact that DCAPS reduces the disk supply voltages in the parallel disk system while making the best effort to guarantee desired response times of the disk requests. Furthermore, it is observed that as the disk request arrival rate increases, the energy consumption of the both parallel disk systems soars.
The Figure below shows that as the load increases, the energy conservation ratio tends to decrease. This result is not surprising because high arrival rates lead to heavily utilized disks, forcing the DCAPS to boos disk voltages to process larger number of requests within their corresponding desired response times. Increasing number of disk request and scaled-up voltages in turn give rise to the increased energy dissipations in the parallel disk systems.

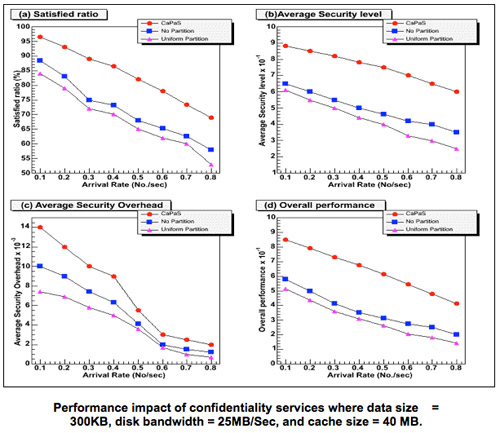
[Nijim et al., 2008b] Cluster storage systems have emerged as high-performance and cost-effective storage infrastructures for large-scale data-intensive applications. Although a large number of cluster storage systems have been implemented, the existing cluster storage systems lack a means to optimize quality of security in dynamically changing environments. We solve this problem by developing a security-aware cache management mechanism (or CaPaS for short) for cluster storage systems. CaPaS aims at achieving high security and desired performance for data-intensive applications running on clusters. CaPaS is used in combination with a security control mechanism that can adapt to changing security requirements and workload conditions, thereby providing high quality of security for cluster storage systems. CaPaS is comprised of a cache partitioning scheme, a response-time estimator, and an adaptive security quality controller. These three components help in increasing quality of security of cluster storage systems while allowing disk requests to be finished before their desired response times. To prove the efficiency of CaPaS, we simulate a cluster storage system into which CaPaS, eight cryptographic, and seven integrity services are integrated. Empirical results show that CaPaS significantly improves overall performance over two baseline strategies by up to 73% with an average of 52% (see the above four Figures).
[Liu et al., 2008b]
Although data duplications may be able to improve the performance of data-intensive applications on data grids, a large number of data replicas inevitably increase energy dissipation in storage resources on the data grids. In order to implement a data grid with high energy efficiency, we address in this study the issue of energy-efficient scheduling for data grids supporting real-time and data-intensive applications. Taking into account both data locations and application properties, we design a novel Distributed Energy-Efficient Scheduler (or DEES for short) that aims to seamlessly integrate the process of scheduling tasks with data placement strategies to provide energy savings. DEES is distributed in the essence - it can successfully schedule tasks and save energy without knowledge of a complete grid state. DEES encompasses three main components: energy-aware ranking, performance-aware scheduling, and energy-aware dispatching. By reducing the amount of data replications and task transfers, DEES effectively saves energy.
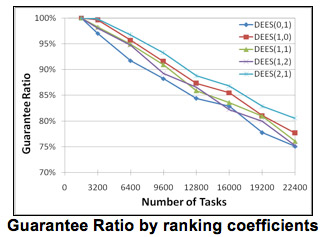
The following Figure shows the performance of DEES using different (ε, μ) value pairs with respect to Guarantee Ratio. It is observed that DEES (2, 1) gives the best performance. This is because DEES (2, 1) takes both goals of meeting deadline and saving energy into account, and put more weight onto the deadline meeting part. Neighbors that can schedule more tasks are given preference. We conclude it is better to give preference to neighbors that can schedule more tasks while consuming satisfactory amount of energy.
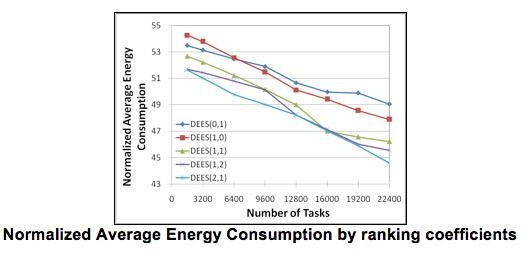
With respect to Normalized Average Energy Consumption, as shown in the following Figure, we observe that DEES (2, 1) consumes the least amount of energy while DEES (0, 1) consumes the most. DEES (2, 1) considers both energy consumption and deadline constraints when dispatching tasks to neighbors. Doing so can reduce the energy cost per task. On the other hand, DEES (0, 1) schedules fewer tasks since it only cares about energy consumption when dispatching tasks. Moreover, given that more tasks miss their deadlines at each site; additional data replications may be needed. Therefore it relatively consumes more energy to replicate data and transfer the tasks.
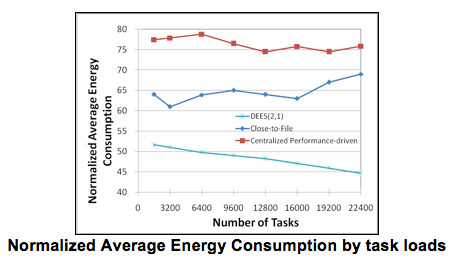
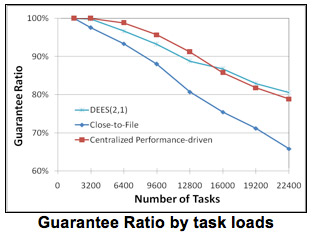
In this experiment set, we compared the performance of DEES with Close-to-Files and Performance-driven algorithms under different task loads. From the Figure below, we observe that DEES yields better performance than Close-to-Files and achieves the same performance level as the Performance-driven algorithm does. The Performance-driven algorithm always schedules a task to a globally best resource that gives the best performance. Since it only focuses on performance but not other factors such as data locality, it yields very good performance with respect to Guarantee Ratio. But the fact that DEES gives similar performance as the Performance-driven algorithm is importance. Thus, DEES not only reduces energy consumption, but it does so without degrading the Guarantee Ratio. One reason is because DEES always schedules tasks with shorter deadlines first. The final criteria for judging whether a task can be scheduled are the task deadlines. Scheduling those tasks with shorter deadlines first makes more tasks schedulable. Moreover, DEES is fully distributed, which is expected to improve the performance when compared to a centralized algorithm, such as the Performance-driven algorithm, especially when the task load is heavy. Given that DESS is fully distributed, while Close-to-Files and Performance-driven algorithms need knowledge of a complete state of the grid, the results make DEES more favorable.
With respect to Normalized Average Energy Consumption, as shown in the Figure below, we see that DEES consumes much less energy per task than Close-to-Files does. On average DEES saves over 35% of energy consumed when compared to the other algorithms. This is because DEES considers the energy consumed to transfer both tasks and data during dispatching. Moreover, DEES groups tasks according to their data accesses and processes tasks on a group basis. Doing so limits the number of data replicas. This is because whenever data is replicated to a remote site, DEES always maximizes utilization of the data replicated by scheduling as many tasks as possible to that remote site. On the other hand, Close-to-Files makes dispatching decisions on a single task basis, which may result in unnecessary data replications. Furthermore, since DEES schedules more tasks than Close-to-Files does, the energy cost per task is expected to be less. The Performance-driven algorithm consumes the most amount of energy due to the fact that it is a greedy algorithm that always schedules a task to a resource giving the best performance, regardless of how much data are needed to be replicated and transferred.