Xiao Qin's Research
Final Report
BUD: A Buffer-Disk Architecture for Energy Conservation in Parallel Disk Systems
Download BUD Annual Report PDF
Findings
An Energy-Efficient Framework for Large-Scale Parallel Storage Systems
A Simulation Framework for Energy-efficient Data Grids
An Energy-Efficient Scheduling Algorithm Using Dynamic Voltage Scaling
for Parallel Applications on Clusters
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Sacrificing Reliability for Energy Saving: Is It Worthwhile for Disk Arrays
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Energy-Efficient Prefetching for Parallel I/O Systems with Buffer Disks
Improving Reliability and Energy Efficiency of Disk Systems via Utilization Control
Energy Conservation for Real-Time Disk Systems with I/O Burstiness
An Adaptive Energy-Conserving Strategy for Parallel Disk Systems
DARAW: A New Write Buffer to Improve Parallel I/O Energy-Efficiency
MICRO: A Multi-level Caching-based Reconstruction Optimization for Mobile Storage Systems
PEARL: Performance, Energy, and Reliability Balanced Dynamic Data Redistribution for Next Generation Disk Arrays
HyBUD: An Energy-Efficient Architecture for Hybrid Parallel Disk Systems
Energy-Aware Prefetching for Parallel Disk Systems
DORA: A Dynamic File Assignment Strategy with Replication
Collaboration-Oriented Data Recovery for Mobile Disk Arrays
A File Assignment Strategy Independent of Workload Characteristic Assumptions
References
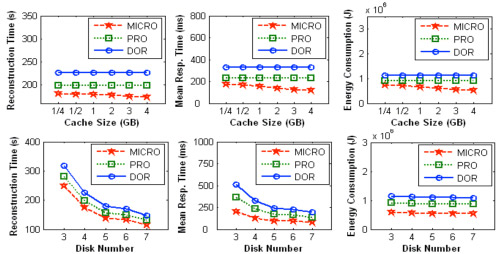
[Xie and Wang, 2008] High performance, highly reliable, and energy-efficient storage systems are essential for mobile data-intensive applications such as remote surgery and mobile data center. Compared with conventional stationary storage systems, mobile disk-array-based storage systems are more prone to disk failures due to their severe application environments. Further, they have very limited power supply. Therefore, data reconstruction algorithms, which are executed in the presence of disk failure, for mobile storage systems must be performance-driven, reliability-aware, and energy-efficient. In this project we developed a novel reconstruction strategy, called multi-level caching-based reconstruction optimization (MICRO), which can be applied to RAID-structured mobile storage systems to noticeably shorten reconstruction times and user response times while saving energy. MICRO collaboratively utilizes storage cache and disk array controller cache to diminish the number of physical disk accesses caused by reconstruction. Experimental results demonstrate that compared with two representative algorithms DOR and PRO, MICRO reduces reconstruction times on average 20.22% and 9.34%, while saving energy no less than 30.4% and 13%, respectively.
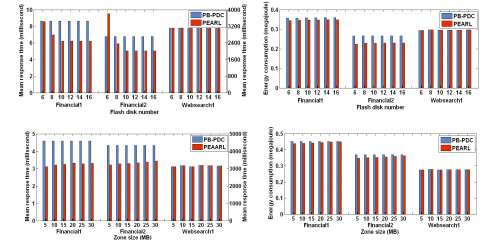
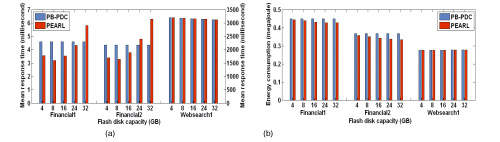
[Xie and Sun, 2008b] Contemporary disk arrays consist purely of hard disk drives, which normally provide huge storage capacities with low-cost and high-throughput for data-intensive applications. Nevertheless, they have some inherent disadvantages such as long access latencies, fragile physical characteristics, and energy-inefficiency due to their build-in mechanical and electronic mechanisms. Flash-memory based solid state disks, on the other hand, although currently more expensive and inadequate in write cycles, offer much faster read accesses and are much more robust and energy efficient. To combine the complementary merits of hard disks and flash disks, in this study we propose a hybrid disk array architecture named HIT (hybrid disk storage) for data-intensive applications. Next, a dynamic data redistribution strategy called PEARL (performance, energy, and reliability balanced), which can periodically redistribute data between flash disks and hard disks to adapt to the changing data access patterns, is developed on top of the HIT architecture. Comprehensive simulations using real-life block-level traces demonstrate that compared with existing data placement techniques, PEARL exhibits its strength in both performance and energy consumption without impairing flash disk reliability.
ECOS: An Energy-Efficient Cluster Storage System [Ruan et al. 2009a] The disks we apply in our prototype are different for the purpose of testing performance of DARAW in different devices. The traces we use are synthetic traces. The arrival rates are generated by exponential distribution. To reflect the real world cases, the traces contain burstnesses and idle time gap inside. Each burstness contains a group of requests whose arrival rates based on exponential distribution. The most appropriate time for buffer disk to dump data to data disk is during idle time gaps. Hence, we will test traces with different idle time gaps and analyse the results.
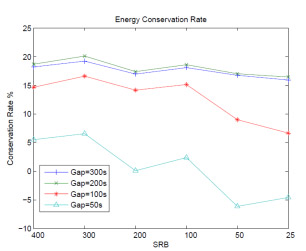
In the above figure, up to more than 20% energy could be conserved when idle time gap between each request burstness is 300 seconds or 200 seconds. When the idle time between each burstness is as short as 50 seconds, the energy conservation rate is not very obvious by using DARAW strategy to buffer data on buffer disks from energy conservation perspective. In the figure, the Sum of Request in Buffer, or SRB, is another important parameter in our experiment. According to DARAW strategy, if the number of bufferred requests which target at one same data disk equals SRB, then the targetted data disk spins up and those requests will be dumped to it. The data disk will spin down when there is no request writting on it. Basically, the larger SRB we set up in DARAW, the more energy we can conserve in the system. However, trace features also can affect the energy conservation rate. The most appropriate time of dumping data to data disks is during idle time gaps. DARAW only dumps data to data disks when SRB requirements resatisfied. If there are too many dumping operations happen during burstness, energy conservation rate will be reduced.
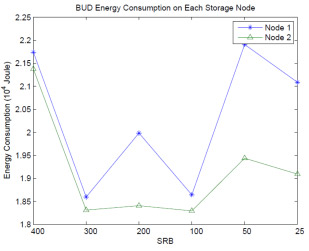
Because idle time gap is low which means workload is high, so dumping data operation is more likely happen during burstnesses (see the above figure). Node 2 is faster than node 1, so the dumping operations will not extend the processing time of buffer disk. In node 1, when dumping operations happen during burstness, since the disks speed in node 1 is not as fast as node 2, the buffer disk needs more time to finish dumping data during burstness. Hence, node 1 consumes more energy in this experiment.
Performance Evaluation of Energy- Efficient Parallel I/O Systems with Write Buffer Disks [Ruan et al. 2009b] [Ruan et al. 2009c] To evaluate the performance of DARAW, we conducted extensive simulation experiments using various disk I/O traces representing real-world workload conditions with small writes. The trace file used in our simulation contains several important parameters such as arrival time, data size, cylinder number, targeting data disk, and arrival time.
Simulator Validation: We used synthetic I/O traces and real-world traces to validate the simulator against a prototype cluster storage system with 12 disks. The energy consumed by the storage system prototype matches closely (within 4 to 13%) to that of the simulated parallel disk system. The validation process gives us confidence that we can customize the simulator to evaluate intriguing energy-efficiency trends in parallel I/O systems by gradually changing system parameters.
For comparison purpose, we consider a baseline algorithm based on a parallel I/O system without the buffer-disks layer. This baseline algorithm attempts to spin up standby target disks upon the arrival of a request. Additionally, the baseline algorithm makes an effort to immediately spin down a disk after it is sitting idle for a period of time. Tables I and II summarize the parameters of two real-world disks (IBM 36z15 Ultrastar and IBM 40GNX Travalstar) simulated in our experiments.
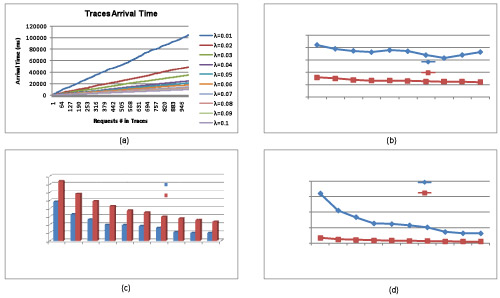
The above figure plots energy efficiency and performance of the baseline algorithm applied to a traditional parallel I/O system without buffer disks. Results plotted in Fig. (a) show that the I/O load increases significantly as the arrival rate (i.e., λ) grows. For example, 1000 requests are issued to the simulated parallel I/O system within 100,000 milliseconds if λ is set to 0.01No./ms., whereas 1000 requests have arrived in the system within 50,000 milliseconds when λ is doubled.
An interesting counterintuitive observation drawn from Fig. (b) is that with respect to the baseline algorithm, the average response time of the high-performance disk (IBM 36z16 Ultrastar) is noticeably longer than that of the IBM 40GNX Travalstar - a low-performance disk. The rationale behind this observation is that the spin-up and spin-down time of IBM Ultrastar is much higher than those of IBM Travalstar. Thus, the overhead incurred by spin-up and spin-down in IBM Ultrastar is more expensive than in IBM Travalstar. Our traces contain a large number of small writes coupled with numerous small idle periods and; therefore, the overhead caused by disk spin up and spin down are even higher than I/O processing times. In other words, the overhead of spin-ups and spin-downs dominates the average response time of disk requests in the parallel storage system.
Fig. (c) shows that the total spin-up times of the Ultrastar disks is smaller than those of the Travalstar disks. We attribute this trend to the fact that the spin-up delay of the IBM Ultrastar disks is much longer than that of the Travalstar disks. Compared with Travalstar, an Ultrastar disk is more likely to serve another request during the time between a spin-up and a consecutive spin-down. As the request arrival rate λ increases, the average inter-arrival time between two continuous requests decreases. In other words, the increasing I/O load gives rise to the decreasing number of spin-ups and spin-downs. Such a trend is apparent for both the IBM Ultrastar and Travalstar disks, because high I/O load can reduce the number of idle time periods, which in turn diminishes opportunities of spinning down disks to conserve energy.
Fig. (d) depicts the energy consumption trend for the IBM Ultrastar and Travalstar disks. In what follows, we describe two important observations. First, Fig. (d) reveals that under the same workload conditions, the overall energy consumption of Ultrastar is higher than that of Travalstar. The Ultrastar disks consume more energy, because compared with Travalstar, Ultrastar not only has higher active and standby power but also has higher spin-up and spin-down energy.. Second, when the request arrival rate λ increases (i.e. heavy workload), the energy consumption is reduced for both Ultrastar and Travalstar. The energy dissipation in the parallel disk system can be minimized by a high I/O load, because a high arrival rate results in low spin-up and spin-down overhead (see Fig. c). It is worth noting that in each experiment, we fix the total number of requests (e.g, 1000).