Xiao Qin's Research
Final Report
BUD: A Buffer-Disk Architecture for Energy Conservation in Parallel Disk Systems
Findings
An Energy-Efficient Framework for Large-Scale Parallel Storage Systems
A Simulation Framework for Energy-efficient Data Grids
An Energy-Efficient Scheduling Algorithm Using Dynamic Voltage Scaling
for Parallel Applications on Clusters
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Sacrificing Reliability for Energy Saving: Is It Worthwhile for Disk Arrays
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Energy-Efficient Prefetching for Parallel I/O Systems with Buffer Disks
Improving Reliability and Energy Efficiency of Disk Systems via Utilization Control
Energy Conservation for Real-Time Disk Systems with I/O Burstiness
An Adaptive Energy-Conserving Strategy for Parallel Disk Systems
DARAW: A New Write Buffer to Improve Parallel I/O Energy-Efficiency
MICRO: A Multi-level Caching-based Reconstruction Optimization for Mobile Storage Systems
PEARL: Performance, Energy, and Reliability Balanced Dynamic Data Redistribution for Next Generation Disk Arrays
HyBUD: An Energy-Efficient Architecture for Hybrid Parallel Disk Systems
Energy-Aware Prefetching for Parallel Disk Systems
DORA: A Dynamic File Assignment Strategy with Replication
Collaboration-Oriented Data Recovery for Mobile Disk Arrays
A File Assignment Strategy Independent of Workload Characteristic Assumptions
References
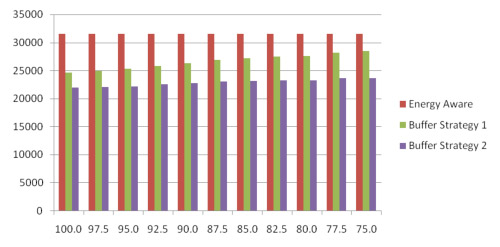
The first buffer disk approach begins to approach the same level of performance as the energy aware strategy. It is only able to save 10% energy over the energy aware strategy when the hit rate is 75%. This is because adding the extra disk puts extra energy requirements on the system, and lowering the hit rate further impacts the energy benefits of the first strategy. The second buffered disk approach is still able perform 25% better than the energy aware approach. This is because there is not the extra energy penalty of adding an extra disk. The capacity of your disk system will be lowered using this approach.
The hit rate becomes a very important factor in the performance of our approaches. If the buffer disk is constantly missing requests then both strategies will eventually downgrade to the energy aware approach. Fortunately applications have been documented to request 20% of the data available 80% of the time. Our heuristic based approach would work considerably well in this case. This is modeled by the 80% hit rate. The buffered disk approach one and two are able to save 12% and 26% energy over the energy aware strategy when the hit rate is 80%. Similarly, they are able to save 37% and 47% of the total energy compared to the non-energy aware approach.
The first buffer disk approach downgrades more quickly than the second approach as the hit rate is decreased as compared to the energy aware approach. This is not that great of a concern since the first strategy is still able to have a positive impact on the reliability of the as compared to the energy aware approach. The first buffer disk approach is still able to produce significant energy savings over the non-energy aware approach without compromising the reliability of the system. The energy savings performance of the second approach does not diminish as quickly as the first approach, but there will be an impact on the capacity of the system. The second approach is also able to reduce the number of state transitions.
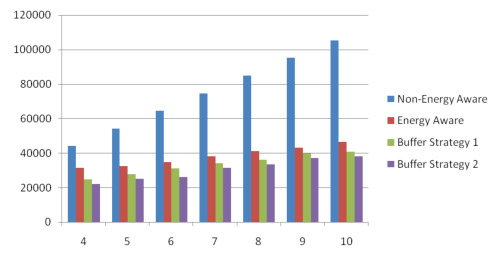
From the above Figure we are able to see that the non-energy aware approach wastes a considerably larger amount of energy as compared to all of the energy aware approaches. This is expected since the non-energy aware approach is not able to place disks in the standby mode. Buffer strategy 1 was able to produce a 12% increase in energy savings over the energy aware strategy when 10 disks were simulated. Similarly, buffer strategy performed even better with an 18% increase. This is expected again because of the energy overhead adding an extra disk Buffer Strategy 1 requires.
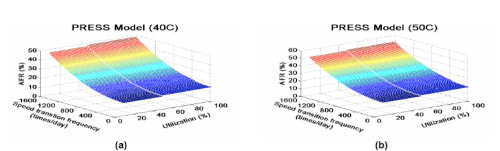
[Xie and Sun, 2008a] Mainstream energy conservation schemes for disk arrays inherently affect the reliability of disks. A thorough understanding of the relationship between energy saving techniques and disk reliability is still an open problem, which prevents effective design of new energy saving techniques and application of existing approaches in reliability-critical environments. As one step towards solving this problem, we investigated an empirical reliability model, called Predictor of Reliability for Energy Saving Schemes (PRESS). The architecture of the PRESS model is given below:

Fed by three energy-saving-related reliability-affecting factors, operating temperature, utilization, and disk speed transition frequency, PRESS estimates the reliability of entire disk array. In what follows, we present two 3-dimennsional figures to represent the PRESS model at operating temperature 40 C (Figure 5a) and 50 C (Figure 5b), respectively.
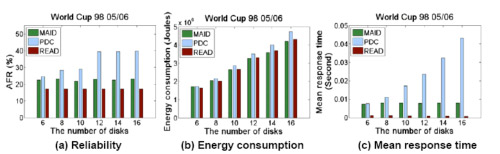
Further, we developed a new energy saving strategy with reliability awareness called Reliability and Energy Aware Distribution (READ) is developed in the light of the insights provided by PRESS. Experimental results demonstrate that compared with existing energy saving schemes, MAID and PDC, READ consistently performs better in performance and reliability while achieving a comparable level of energy consumption.
[Xie and Sun, 2007] Many real-world applications like Video-On-Demand (VOD) and Web servers require prompt responses to access requests. However, with an explosive increase of data volume and the emerging of faster disks with higher power requirements, energy consumption of disk based storage systems has become a salient issue. To achieve energy-conservation and prompt responses simultaneously, in this study we propose a novel energy-saving data placement strategy, called Striping-based Energy-Aware (SEA), which can be applied to RAID-structured storage systems to noticeably save energy while providing quick responses. Further, we implement two SEA-powered RAID-based data placement algorithms, SEA0 and SEA5, by incorporating the SEA strategy into RAID-0 and RAID-5, respectively. Extensive experimental results demonstrate that (see the three figures below) compared with three well-known data placement algorithms Greedy, SP, and HP, SEA0 and SEA5 reduce mean response time on average at least 52.15% and 48.04% while saving energy on average no less than 10.12% and 9.35%, respectively.

[Xie, 2007] and [Madathil et al., 2008] The problem of statically assigning nonpartitioned files in a parallel I/O system has been extensively investigated. A basic workload characteristic assumption of existing solutions to the problem is that there exists a strong inverse correlation between file access frequency and file size. In other words, the most popular files are typically small in size, while the large files are relatively unpopular. Recent studies on the characteristics of web proxy traces suggested, however, the correlation, if any, is so weak that it can be ignored.
Hence, in this part of study, we raised the following two questions. First, can existing algorithms still perform well when the workload assumption does not hold? Second, if not, can one develop a new file assignment strategy that is immune to the workload assumption? To answer these questions, in this project we first evaluated the performance of three well-known file assignment algorithms with and without the workload assumption, respectively. Next, we developed a novel static file assignment strategy for parallel I/O systems, called static round-robin (SOR), which is immune to the workload assumption.

The above four figures show the simulation results for the four algorithms on a parallel I/O disk array with 16 disk drives. We observe that SOR consistently outperforms the three exiting approaches in terms of mean response time. This is because SOR considers both minimizing variance of service time for each disk and fine-tuning load balancing degree. Consequently, the sorted files were continuously assigned to disks such that a more evenly distributed workload allocation scheme was generated. SP takes the second place in mean response time metric, which is consistent with our expectation because it is one of the best existing static file assignment heuristics. To clearly demonstrate the performance improvement, Fig. 2b provides mean response time decrease gained by SOR compared with Greedy, SP, HP, respectively. In particular, SOR can reduce mean response time on average by 1118.3, 1052.8, and 269.6 seconds, compared with HP, Greedy, and SP, respectively. An interesting observation is that the mean response time improvement becomes more significant when the overall workload represented by the aggregate access rate increases. The implication is that SOR exhibits its strength in situations where system workload is heavy. In terms of mean slowdown, SOR also performs best among the four heuristics (Fig. c), which is consistent with the results shown in Fig. a. Since the total workload is relatively heavy, the mean disk utilization in Fig. d quickly arises to 1 when aggregate access rate is larger than 25 (1/second).