Xiao Qin's Research
Final Report
BUD: A Buffer-Disk Architecture for Energy Conservation in Parallel Disk Systems
Findings
An Energy-Efficient Framework for Large-Scale Parallel Storage Systems
A Simulation Framework for Energy-efficient Data Grids
An Energy-Efficient Scheduling Algorithm Using Dynamic Voltage Scaling
for Parallel Applications on Clusters
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Sacrificing Reliability for Energy Saving: Is It Worthwhile for Disk Arrays
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Energy-Efficient Prefetching for Parallel I/O Systems with Buffer Disks
Improving Reliability and Energy Efficiency of Disk Systems via Utilization Control
Energy Conservation for Real-Time Disk Systems with I/O Burstiness
An Adaptive Energy-Conserving Strategy for Parallel Disk Systems
DARAW: A New Write Buffer to Improve Parallel I/O Energy-Efficiency
MICRO: A Multi-level Caching-based Reconstruction Optimization for Mobile Storage Systems
PEARL: Performance, Energy, and Reliability Balanced Dynamic Data Redistribution for Next Generation Disk Arrays
HyBUD: An Energy-Efficient Architecture for Hybrid Parallel Disk Systems
Energy-Aware Prefetching for Parallel Disk Systems
DORA: A Dynamic File Assignment Strategy with Replication
Collaboration-Oriented Data Recovery for Mobile Disk Arrays
A File Assignment Strategy Independent of Workload Characteristic Assumptions
References
[Zong et al., 2008] [Zong et al., to be published] To conserve energy, BUD makes an effort to place most data disks will run in the low power state, thereby directing most traffic to a limited number of buffer disks. This can potentially make the buffer disks overloaded and become the performance bottleneck. Load balancing is one of the best solutions for the inherent shortcoming of the BUD architecture. Basically, there are three types of load balancing strategies called non-random load balancing, random load balancing, and redundancy load balancing. Sequential mapping belongs to non-random load balancing, because the buffer disks have fixed mapping relationships with specific data disks. The round-robin mapping is a typical random load balancing strategy by allocating data to each buffer disk with equal portions and in order. Redundancy load balancing strategies for storage systems include EERAID, eRAID, and RIMAC. We designed a heat-based load balancing strategy, which is also a random load balancing strategy. The primary objective of our strategy is to minimize the overall response time of disk requests by keeping all buffer disks equally loaded.
In contrast to sequential and round robin mapping algorithms, a heat-based mapping strategy is proposed to achieve load balancing among buffer disks. The basic idea of heat-based mapping is that blocks in data disks are mapped to buffer disks based on their heat, i.e. frequencies of accesses. Our goal is to make the accumulated heat of data blocks allocated to each buffer disk the same or close to this ideal situation. In other words, the temperature, or the workload of each buffer disk should be the same. The temperature of a buffer disk is the total heat of all blocks existing in the buffer disk. For example, suppose all blocks have the same data size, the heat of blocks 1-6 is 5, 4, 1, 2, 1, and 2, respectively. Then, block 1 is cached to buffer disk 1, blocks 2 and 3 are copied to buffer disk 2 and blocks 4, 5 and 6 are mapped to buffer disk 3. With this mapping in place, the temperature of each buffer disk is 5.
This algorithm will periodically collect the requests waiting in the queue, analyze the target block of each read request, and calculate the heat of each unique block. If the target block cannot be found in the buffer disk, the controller initiates a data miss command. This in turn will wake up the corresponding data disk in order to copy the block to the buffer disk that has the lowest temperature. In a special case, the selected buffer disk may not have free space to store a new data block. The controller will seek the next buffer disk with a temperature that is higher than the initial buffer disk selected, but still lower than any other buffer disks. In the worst case, no candidate buffer disk will be found because all buffer disks are full. A data replacement function using the Least Recently Used (LRU) algorithm will be executed to evict some existing data blocks. If the target block has already been cached in one of the buffer disks, then that buffer disk will serve the corresponding request. Once the algorithm has made the decision how to dispatch these requests, the block heat and buffer disk temperature need to be recalculated and updated accordingly. Since this is an online algorithm, the decision made at the current time period relies on the heat and temperature information collected in the last time period.
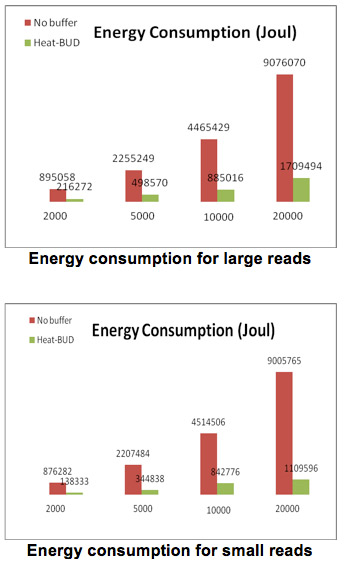
This set of experimental results aims at evaluating the energy efficiency of the buffer disk based parallel storage systems. To fairly compare the results, we generated and executed a large number of requests and simulated both large reads (average data size is 64MB) and small reads (average data size is 64KB). The following two Figures plot the total energy consumption of NO-buffer and Heat-BUD running 2000, 5000, 10000, and 20000 large read requests and small read requests, respectively. There are three important observations here. First, the BUD can significantly conserve energy compared with No-Buffer parallel storage systems. Second, the more requests BUD serves, the more potential power savings is revealed. For example, BUD outperforms No-Buffer in terms of energy conservation by 75.83%, 77.89%, 80.18% and 81.16% for 2000, 5000, 10000, and 20000 large reads, respectively. This is expected because more requests lead to more opportunities for BUD to keep the data disks in the sleep state. Third, BUD performs better for small reads (average 84.4% improvement) than large reads (average 78.77% improvement). The reason is that BUD consumes more energy when moving large data blocks to buffer disks.
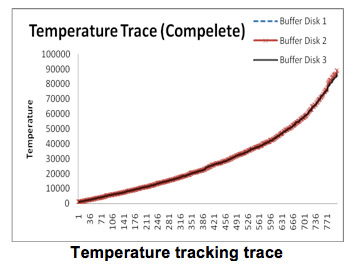
In this part of the study, we evaluated the load balancing ability of the heat-based algorithm. Recall that the temperature of a buffer disk clearly indicates how busy it is. The Figure below records the temperature of three buffer disks when BUD is processing 800 requests. We can see that the three temperature curves merge together most of the time, which means that the three buffer disks are almost equally loaded for most of the simulation time.
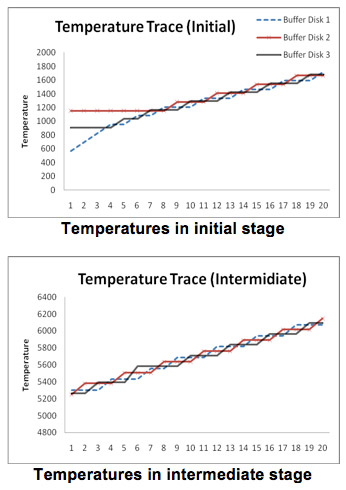
In order to identify the information hidden in the above Figure and understand how the dynamic load balancing works, we plot the initial stage, intermediate stage of the temperature tracking trace in the following two Figures. At the initial stage, the three buffer disks are not load balanced. Buffer disk 2 is the busiest disk and buffer disk 1 is lightly loaded. Therefore, the heat-based algorithm will keep allocating requests to buffer disk 1. We observe that the temperature of buffer disk 1 keeps growing and it catches buffer disk 3 first. After that, the temperatures of buffer disk 1 and 3 cross-rise for a while and then they catch buffer disk 2. At this point, the system is load balanced for the first time. Fig. 5 shows that the entire system is perfectly load balanced in the intermediate stage because the temperatures of three buffer disks rise in turns.
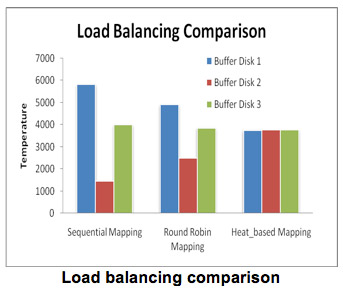
To compare the load balancing efficiency of sequential mapping, round robin mapping, and heat-based mapping, we tested 2500 requests with average data size of 4MB using these three mapping strategies. The simulation results depicted in the Figure below prove that our heat-based mapping is the most efficient algorithm that achieves load balancing. In addition, the random mapping method (e.g., round robin mapping) outperforms non-random mapping strategies (e.g., sequential mapping) in terms of load balancing.