Xiao Qin's Research
Final Report
BUD: A Buffer-Disk Architecture for Energy Conservation in Parallel Disk Systems
Findings
An Energy-Efficient Framework for Large-Scale Parallel Storage Systems
A Simulation Framework for Energy-efficient Data Grids
An Energy-Efficient Scheduling Algorithm Using Dynamic Voltage Scaling
for Parallel Applications on Clusters
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Sacrificing Reliability for Energy Saving: Is It Worthwhile for Disk Arrays
Load-Balancing Strategies for Energy-Efficient Parallel Storage Systems with Buffer Disks
Energy-Efficient Prefetching for Parallel I/O Systems with Buffer Disks
Improving Reliability and Energy Efficiency of Disk Systems via Utilization Control
Energy Conservation for Real-Time Disk Systems with I/O Burstiness
An Adaptive Energy-Conserving Strategy for Parallel Disk Systems
DARAW: A New Write Buffer to Improve Parallel I/O Energy-Efficiency
MICRO: A Multi-level Caching-based Reconstruction Optimization for Mobile Storage Systems
PEARL: Performance, Energy, and Reliability Balanced Dynamic Data Redistribution for Next Generation Disk Arrays
HyBUD: An Energy-Efficient Architecture for Hybrid Parallel Disk Systems
Energy-Aware Prefetching for Parallel Disk Systems
DORA: A Dynamic File Assignment Strategy with Replication
Collaboration-Oriented Data Recovery for Mobile Disk Arrays
A File Assignment Strategy Independent of Workload Characteristic Assumptions
References
TADVS consistently consumes less energy regardless of the value of CCR (Communication-Computation Ratio) [Ruan et al., 2007]. For example, TADVS conserves the energy consumption for the SPA application by up to 16.8% with an average of 10.7%. When one increases CCR from 0.1 to 1, the energy consumption gradually goes up. This can be explained by the fact that a high CCR results in high communication cost, which in turn leads to the increased total energy consumption. More interestingly, we observe from Fig. 4 that energy savings achieved by the TADVS strategy become more pronounced when the communication intensity is relatively low. This result clearly indicates that low communication intensity offers more space for TADVS to reduce voltage supplies of computing nodes to significantly conserve energy. In other words, applications with low communication intensities can greatly benefit from the TADVS scheduling scheme.

Figure below shows the energy consumption caused by the Gaussian application on the cluster with Intel Pentium 4 processors, whereas First of all, the experimental results reveal that TADVS can save energy consumption for the Gaussian application by up to 14.8% with an average of 9.6%. Second, the results plotted in Figs. 5 and 6 show that compared the Gaussian application with the SPA application, the energy saving rate of TADVS is less sensitive to the communication intensity. The empirical results suggest that the sensitivity of the energy saving rate of TADVS on communication intensity partially relies on the characteristics of parallel applications. Note that parallel applications’ characteristics include parallelism degrees, number of messages, average message size, and the like. Compared with the SPA application (Fig. 1), the Gaussian application has a higher parallelism degree. More specifically, we concluded from the experimental results shown in Figs. 4 and 6 that the energy saving rate of TADVS is less sensitive to the communication intensity of parallel applications with higher parallel degrees. Moreover, parallel applications with higher parallelism degrees are able to take more advantages from the TADVS in terms of energy conservation. A practical implication of this observation is that although high communication intensities of parallel applications tends to reduce energy saving rates of TADVS, increasing parallel degrees of the parallel applications can potentially and noticeably boost up the energy saving rates.
[Zong et al., 2007d] High performance clusters and parallel computing technology are experiencing their golden ages because of the convergence of four critical momentums: high performance microprocessors, high-speed networks, middleware tools, and highly increased needs of computing capability. With forceful aid of cluster computing technology, complicated scientific and commercial applications like human genome sequence programs, universe dark matter observation and the Google search engine have been widely deployed and applied. Although clusters are cost-effective high-performance computing platforms, energy dissipation in large clusters is excessively high. Most previous studies in cluster computing focused on performance, security, and reliability, completely ignoring the issue of energy conservation. Therefore, designing energy-efficient algorithms for clusters, especially for heterogeneous clusters, becomes highly desirable. This year, we developed two novel scheduling strategies, called Energy-Efficient Task Duplication Scheduling (EETDS) and Heterogeneous Energy-Aware Duplication Scheduling (HEADUS), which attempt to make the best tradeoffs between performance and energy savings for parallel applications running on heterogeneous clusters. Our algorithms are based on the duplication-based heuristics, which are efficient solutions to minimize communication overheads among precedence constrained parallel tasks. Our algorithms consist of two major phases. Phase one is used to optimize performance of parallel applications and the second phase aims to provide significant energy savings. We present extensive simulation results using realistic parallel applications to prove the efficiency of our algorithm.
[Zong et al., to be published] Improve performance and conserve energy are two conflict objectives in parallel storage systems. In this project, we proposed a novel solution to achieve the twin objectives of maximizing performance and minimizing energy consumption of large scale parallel disk arrays. We observed that buffer disks can be a performance bottleneck of an energy-efficient parallel disk system. We developed a heat-based and duplication-enabled load balancing strategies to successfully overcome the natural shortcoming of the BUD architecture, in which the limited number of buffer disks are very likely become the bottleneck.
The basic idea of heat-based mapping is that blocks in data disks will be mapped to buffer disks based on their heat (access frequency). Our goal is to make the accumulated heat of data blocks allocated to each buffer disk is exactly the same or at least close. In other words, the temperature of each buffer disk should be in the same level. Here the temperature of a buffer disk means the total heat of all blocks existing in this buffer disk. For example, in current request queue, the heat of block 1-6 are 5, 4, 1, 2, 1, 2 respectively. Therefore, block 1 is cashed to buffer disk 1, block 2 and 3 are copied to buffer disk 2 and block 4, 5 and 6 are mapped to buffer disk 3. In this way, the temperature of each buffer disk is 5. The following figure depicts the dispatch results of heat-based load balancing strategy. Note that there are 15 requests cashed in the RAM buffer and they are going to be dispatched to different buffer disks by the controller. Requests have different colors, which represents they will access different data blocks. For example, request 1 will access the data block1 existing in data disk 1 and request 6 will access the data block6 existing in data disk 6.
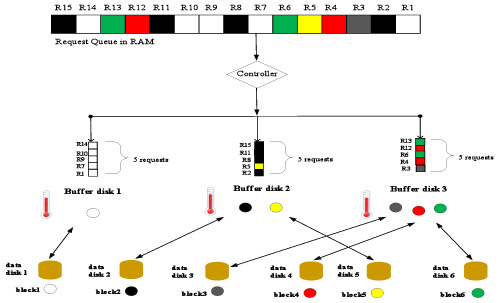
The following figure shows another way to do load balancing, i.e. we can duplicate the most popular data blocks to several buffer disks. The basic idea of duplication based load balancing is to move multiple replicas of “hot” data blocks to different buffer disks, which allow multiple buffer disks to serve the requests in parallel thereby improving the performance. In this example, the controller generates a load balanced dispatching by duplicating block 3 in each of the three buffer disks. To decide which block should be duplicated, we also need to calculate and order the heat of data blocks.

To validate the efficiency of the proposed framework and load balancing strategies, we conduct extensive simulations using both synthetic workload and real-life traces.
[Manzanares et al., to be published] Large-scale parallel disk systems are frequently used to meet the demands of information systems requiring high storage capacities. A critical problem with these large-scale parallel disk systems is the fact that disks consume a significant amount of energy. To design economically attractive and environmentally friendly parallel disk systems, we developed two energy-aware prefetching strategies (or PRE-BUD for short) for parallel I/O systems with disk buffers.
First, we studied a concrete example, which is based on the synthetic disk trace presented in the table below.
Synthetic Trace
| Time | 0 | 5 | 10 | 15 | 20 | 25 | 30 | 35 | 40 | 45 | 50 | 55 | 60 | 65 | 70 | 75 | 80 | 85 | 90 | 95 |
| Block | A1 | A2 | B1 | B2 | D1 | D2 | C1 | C2 | B2 | B1 | A1 | A2 | C1 | C2 | D1 | D2 | B2 | B1 | A1 | A2 |
Disk Parameters (IBM 36Z15)
| X = Transfer Rate =55 MB/s | P |
| P |
P |
| E |
E |
| T |
T |
The requests all have the size of 275MB. This means each request will take approximately 5s to complete. This length was chosen, so seek and rotational delays would be negligible. There are N=4 disks used in this example, where each disk is given a unique letter. Each disk has two different data sections requested multiple times throughout the example. The example demonstrates only large sequential reads. This was also chosen to simplify our example to allow us to demonstrate the potential benefits of our approach. We also assume that all the data can be buffered which causes a small percentage of data to be accessed 100% of the time. This is only used for our motivational example and our simulation results vary this parameter to model real-world conditions. We also assume these strategies can be handled off-line meaning we have prior knowledge of the complete disk request pattern.
Non-Energy Aware Results
| T |
70s | T |
70s |
| T |
80s | T |
80s |
| T |
30s | T |
30s |
| T |
20s | T |
20s |
| E |
0J | E |
0J |
| E |
0J | E |
0J |
| T |
1119J | T |
1119J |
| T |
1086J | T |
1086J |
| T |
4410J |
Energy Aware Results
| T |
0s | T |
10s |
| T |
0s | T |
0s |
| T |
30s | T |
30s |
| T |
20s | T |
20s |
| T |
45.2s | T |
33.7s |
| T |
53.7s | T |
53.7s |
| E |
296J | E |
309J |
| E |
309J | 309J | |
| T |
814J | T |
900.25J |
| T |
713.25J | T |
713.25J |
| T |
3140.75J |
PRE-BUD Approach 1
| T |
0s | T |
0s |
| T |
0s | T |
0s |
| T |
10s | T |
10s |
| T |
10s | T |
10s |
| T |
100s | T |
100s |
| T |
100s | T |
100s |
| E |
13J | E |
13J |
| E |
13J | 13J | |
| T |
398J | T |
398J |
| T |
398J | T |
398J |
| BD |
540 | BD |
1350J |
| T |
3482J |
PRE-BUD Approach 2
| T |
0s | T |
0s |
| T |
0s | T |
0s |
| T |
140s | T |
10s |
| T |
10s | T |
10s |
| T |
0s | T |
100s |
| T |
100s | T |
100s |
| E |
0J | E |
13J |
| E |
13J | 13J | |
| T |
1890J | T |
398J |
| T |
398J | T |
398J |
| BD |
540 | BD |
1350J |
| T |
3084J |
The results presented in the above four Tables gave us some promising initial results. The two approaches using a buffer disk provided significant energy savings over the non-energy aware parallel disk storage system. This has the benefit of not impacting the capacity of the large-scale parallel disk system. The other main benefit of our first approach is the fact that state transitions are lowered as compared to the energy aware baseline.
Second, we design a prefetching approach that utilizes an extra disk to accommodate prefetched data. Third, we develop a second prefetching strategy that makes use of an existing disk in the parallel disk system as a buffer disk. Compared with the first prefetching scheme, the second approach lowers the capacity of the parallel disk system. However, the second approach is more cost-effective and energy-efficient than the first prefetching technique.
Finally, we quantitatively compare both of our prefetching approaches against two conventional strategies including a dynamic power management technique and a non-energy-aware scheme. The results obtained from the Figure below held the number of disks to 4 and also kept the data size of each request at 275MB. We have omitted the results of the non-energy aware approach, since they are constant and higher than the energy aware strategy. As expected the performance of both of our strategies were lowered when the hit rate was decreased. This is expected since our motivational example demonstrated a best case scenario. Disk sleep times are lowered once a miss is encountered. This is due to the fact that a disk has to wake up to serve the request. This will increase the energy consumption of disks that have to serve the missed requests. This leads to an increase in the total energy consumption of the entire system. Our buffered large-scale parallel disk system is still able to consume less energy than the energy aware approach. The energy aware and non-energy aware disk systems are not affected by buffer disk miss rates.